


How It's Done: DNA Replication
- Aarushi Gupta

- Dec 19, 2019
- 7 min read
Updated: May 23, 2020
This week’s post will be another Biology class. This is the last assignment we have for the semester and I’m really happy. We’ve been learning about Molecular Genetics, so for the next 3 posts, that will be our topic of discussion. You can sit back and relax or grab a pen and some paper to take notes. Let’s begin.
Before delving into DNA replication, it is important to know what DNA really is. We always talk about it being the carrier of genetic information. If you have Grade 10 or 11 Science/Biology, you know that cells split to make new cells, which is mitosis, and male and female germline cells fuse to form a zygote, which happens because of meiosis. But what role does DNA play and how does so much DNA fit into the tiny nuclei of cells?
Deoxyribonucleic Acid in its most basic form is a long strand of repeating monomers called nucleotides. Each nucleotide consists of one phosphate group, one ribose sugar and one nitrogenous base. A nucleotide bonds with other nucleotides, either with a phosphodiester bond, from the 3’ Carbon to the next phosphate, or with hydrogen bonds, between complementary nitrogenous bases. The attractions between the nucleotides result in a double helix structure. Several nucleotides, around 147, wrap themselves around 8 pieces of proteins, together called a histone, and the DNA-histone complex is called a nucleosome. 6 nucleosomes form a tightly grouped complex, called a solenoid, similar to the one you may learn about in Physics. The solenoids’ structure reduces the volume of the DNA and makes it small enough to fit in the nucleus. The solenoids wrap around themselves and the final structure we see is the chromosome.

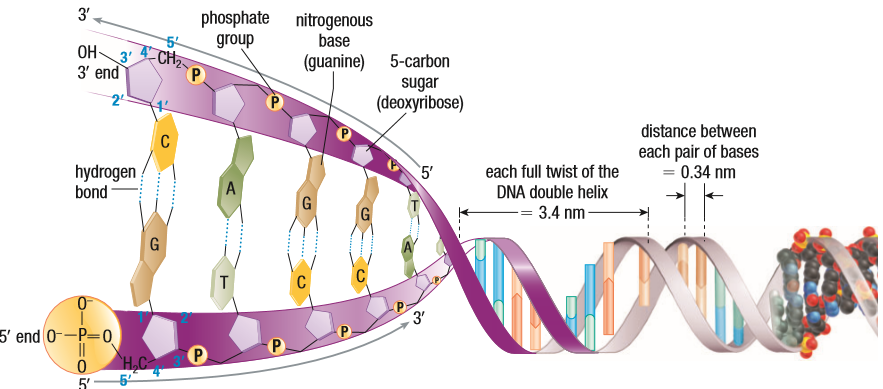
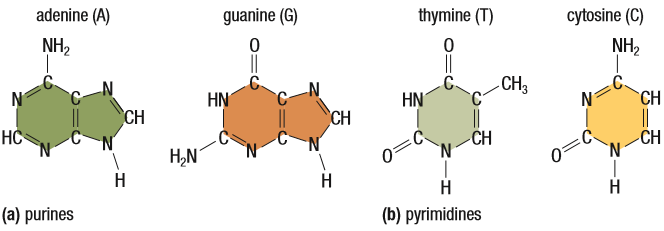
Note: This is some additional, required information to understand the rest of this post. One: complementary base pair. There are two types of bases, purines (double-ringed) and pyrimidines (single-ringed). The bases used in DNA nucleotides are Adenine, Guanine, Cytosine and Thymine. A and G are purines and C and T are pyrimidines. If you are looking for complementary base pairs, it’s logical one will be a purine and the other, a pyrimidine. A and T are complementary, joined by 2 H-bonds. G and C are complementary, joined by 3 H-bonds.
Next, we need to understand the structure of DNA. The ribose sugar has 5 Carbons: 1’, 2’, 3’ 4’ 5’. 3’ and 5’ are our focus here. 3’ and 5’ are always joined to a phosphate unless it’s the end of a strand. The strand starts with the 5’ open and not joined to anything and the 3’ at the end, also not joined to anything. Because of the complementary base pairing, and to maintain the structural integrity of DNA, the strands run antiparallel, which means, when going left to right, one strand is 5’ to 3’ and the other is 3’ to 5’. In a ribose sugar, all Carbons have -OH attached to them. But in DNA, the sugar is missing an O on the 3’ Carbon. This allows the sugar to bond with a phosphate group of another nucleotide, eventually making a chain of nucleotides. This is why 3’ is essential to replication.
DNA is, as established above, a bunch of nucleotides grouped together. But the grouping is not random. A gene, or a sequence of DNA, is responsible for the production of a certain polypeptide. We know that when enough polypeptides are group together in the right way, a protein is formed. So, genes are, essentially, instructions for making proteins. These proteins give rise to our traits. It’s a fascinating concept but, unfortunately, won’t be the focus of this post. The focus is how the cell makes enough DNA for a parent cell and its daughter cell during cell replication.
If you have had a Gr. 10/11 Science class, you’ll know that the steps in Mitosis and Meiosis are Interphase, Prophase, Metaphase, Anaphase and Telophase. Today’s focus will be the S stage, or Synthesis stage, of Interphase. This gets a little complicated from here.
One thing to understand is that DNA Replication is a semi-conservative. This means that for a 2 stranded DNA molecule, the new, replicated copy will have a parent strand (a strand from the original DNA molecule) and a complementary copy. If the process were conservative, replication would happen, but the parent strand would go back to being together and the replicated strands would go together as the new copy. This would give rise to too much error, so the cell machinery keeps the process semi-conservative.
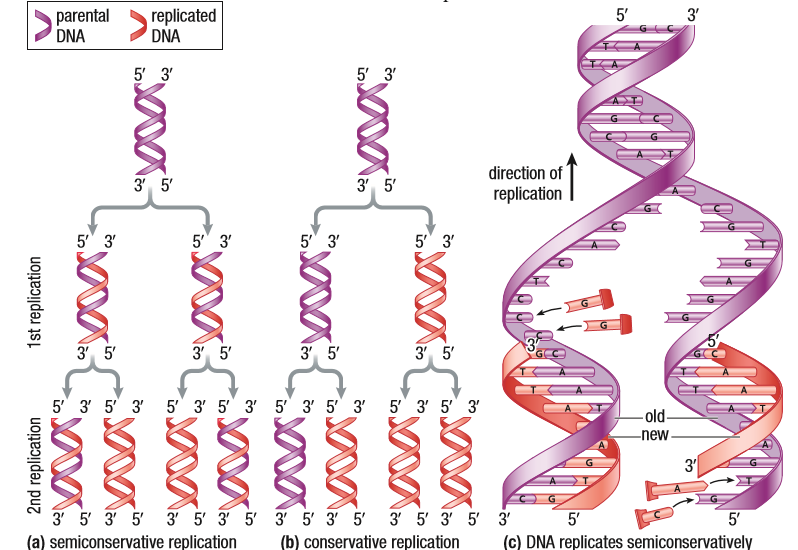
There are 3 steps in DNA Replication:
1. Strand Separation
2. Building Complementary Strands
3. Proofreading and Error Repair
1. Strand Separation:
The figure shows the DNA molecule with one strand going 5’ to 3’ and the other going from 3’ to 5’. An enzyme, DNA helicase, comes to a certain point in the molecule and that point is known as the replication origin. We’ll talk about this happening in one point, but due to the length of DNA, it happens in multiple locations at once. The function of the helicase is to unwind the DNA. This happens with it’s ability to break the hydrogen bonds between the complementary bases. This makes a Y-shaped replication fork.
Two problems arise here. One: as the helicase continues to unwind the DNA, the still wound DNA on the other side begins to twist and tangle. This is fixed with topoisomerases. They are proteins that cut the strand near the replication fork and allow them to unwind. The cut part of the strand rejoins the whole strand because of its attractions. Two: the helicase breaks the H-bonds between the complementary bases, but the attraction is strong enough for the bonds to form again, right away. This is fixed with the help of Single Strand Binding proteins, SSBs. They bind to the nucleotides on each side and prevent the strands from annealing or coming together again.
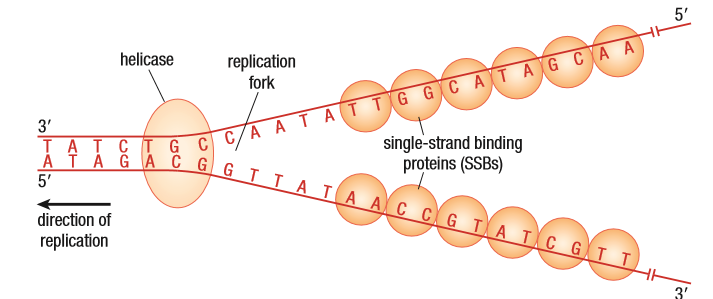
2. Building Complementary Strands:
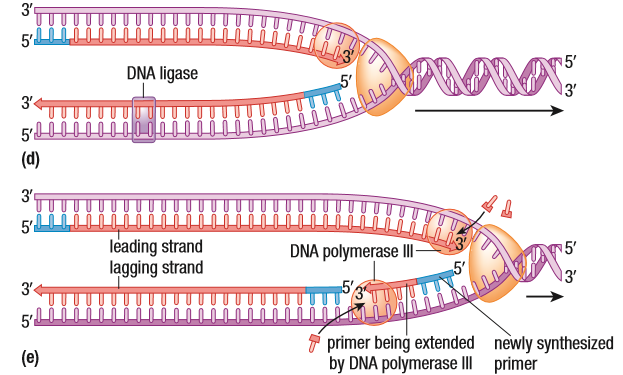
A lot happens in this step. Let’s establish the enzymes used first, so you can predict what happens. We use RNA primase, DNA Polymerase III, I and II (in that order) and DNA ligase. The two separated strands sit, going 5’ to 3’ and 3’ to 5’. This is important to know. No matter which way the DNA helicase is splitting the DNA, whichever way the direction of replication is, DNA polymerase III will only read the DNA in a 3’ to 5’ direction. The complementary strand will always be 5’ to 3’ because that is how replication works. DNA polymerase III also needs a location with a double strand to attach to, before working. But, because the helicase has already separated the strands, a short RNA primer is added, by the RNA primase, to the beginning of the strand. The Polymerase III will begin to read the strand and, as it moves along, it starts to form a chain of nucleotides complementary to the ones it reads. The strand is 5’ to 3’ because the new nucleotides are always added to the 3’ end. Because of this requirement, there always one 3’ to 5’ strand that goes in the direction of the replication, or in the direction of the Helicase’s movement. So, it follows the replication fork. This way, the polymerase III doesn’t have to detach. It continues to replicate the template strand as long as the parent strands are separated.
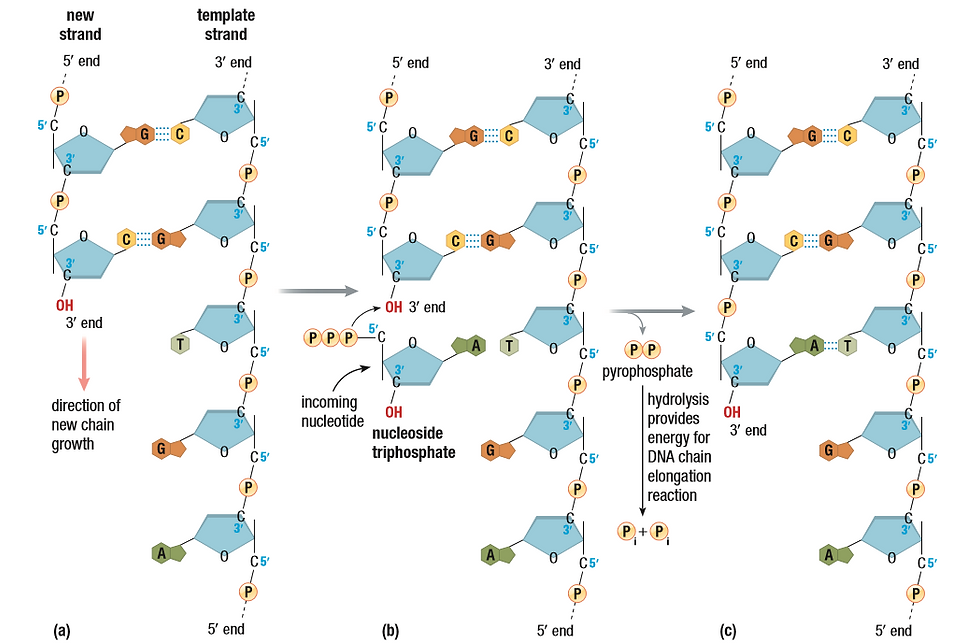
The other strand, the 5’ to 3’ requires additional work. (I will try to explain this as well as I can, but it’s a lot to wrap your head around. Maybe a video may help). The 5’ to 3’ strand is still a 3’ to 5’ from another perspective. But, with respect to the replication fork, it’s 5’ to 3’. Near the replication fork, the RNA primase adds a short primer for the polymerase III to attach to. The polymerase III replicates the strand until it hits the next primer, which is when it detaches. DNA polymerase comes and replaces the RNA primer the PIII hit with DNA. DNA ligase comes and creates a phosphodiester between the now DNA and the next DNA fragment. The image below might help. The DNA fragment made by PIII is called an Okazaki Fragment, named after the couple that discovered it.
Note: the process of replication requires energy. DNA Replication uses molecules called deoxy-nucleotide triphosphates (dNTPs) to combat this. They are similar to ATPs. When the polymerase III brings a dNTP to be joined with the chain of nucleotides, a hydrolysis reaction cleaves 2 of the 3 phosphates off the dNTP. Enough energy is produced to power the whole reaction.
The 3’ to 5’ strand is always the leading strand and it’s continuous, whereas the 5’ to 3’ strand is the lagging strand and it’s discontinuous. It’s made piece by piece.

3. Error Repair
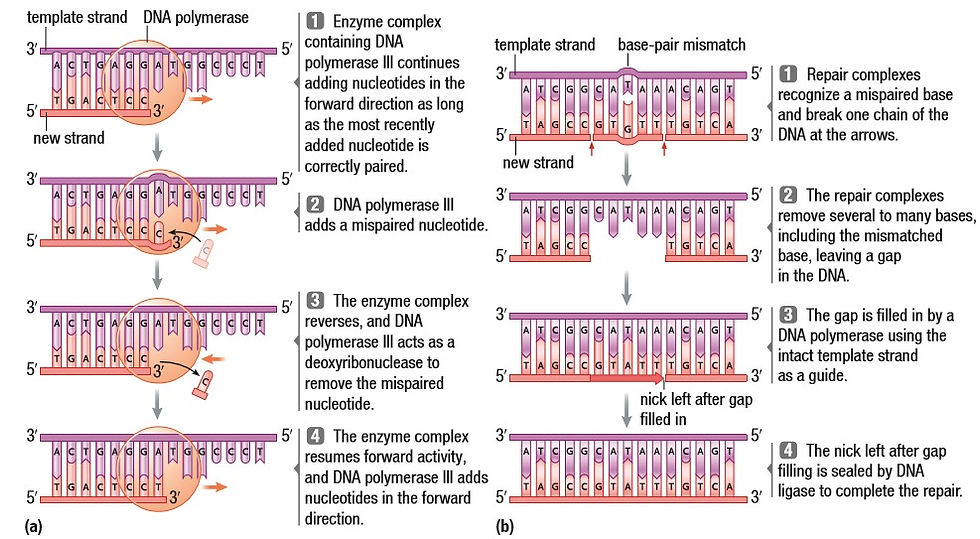
DNA Polymerase III will proofread while it is replicating a strand. When it recognizes a misconfiguration in the DNA, it backs up and fixes it before moving on. But it’s not perfect at proofreading. So, DNA polymerase II comes in to help. It’s a slow enzyme but it reduces the rate of error to 1 in 100 million base pairs.
The above is mostly based on Prokaryotic DNA replication because of how simple the prokaryote is but Eukaryotic Replication isn’t too different.
Prokaryotes also have a DNA sequence separate from their ‘nuclear’ DNA, called the plasmid. It’s a loop of DNA that helps it pass genes to offspring or to nearby organisms. It doesn’t have histones or solenoids, so it reduces the volume of the DNA by twisting it.
Lastly, we’ll discuss telomeres. At the end of a lagging strand is a RNA primer that doesn’t get converted to DNA. One of the functions of telomeres is to prevent any coding DNA from being lost due to this. Telomeres are repeating sequences of DNA, of which small parts, about 100 nucleotides, are cut off at the end of replication. Other than that, they prevent chromosome ends from fusing together. They prevent DNA degradation that may be caused by nucleases. And they give us an idea of how many times the cell can divide. The Hayflick limit is the total number of times a cell can divide. This is important because once that number is crossed and DNA replication begins to affect the coding regions, cell senescence begins. In basic terms, it is cell aging. The cell stops functioning and replicating normally.

Telomeres are related to cancerous cells. A normal cell functions until it runs out of telomeres. After that, it dies. An enzyme, called telomerase, that promotes the growth of telomeres, is essential in germline cells because they must stay active for a long time. This enzyme is not found in somatic cells which is why they die. Cancerous cells produce telomerase, which is why they replicate so quickly and are harder to get rid of. The growing mass of cells interferes with the functioning of the rest of the body and causes life-threatening diseases.
This was a long chapter and there is definitely a lot more you can learn from it. Let me know if you want to. The next post will be up very soon. Stay tuned. - Aarushi.
APA Citation:
Fraser, D., LeDrew, B., Vavitsas, A., White-McMahon, M. (2012). Biology 12. Toronto: Nelson Education Ltd.



Comments