


How It's Done: Transcription and Translation
- Aarushi Gupta

- Dec 19, 2019
- 10 min read
The second part of my study aide will talk about the importance of genes. What does the cell do with all that DNA that we discussed about in the previous post? It uses the genes as instructions to make the necessary proteins. In this post, we’ll be covering DNA Transcription and Translation, along with Gene Expression, Mutations and Viruses.
In the previous post, we talked about DNA Replication. DNA is a long sequence of nucleotides. The nucleotides make up sequences called genes that give the cell instructions to make all kinds of proteins. Here is a table of the uses proteins have withing the cells and in the body
Some basics to know before we begin protein synthesis:
1. One gene is said to code for one polypeptide. If you have taken higher level Biology, you know that there are 4 structures of proteins: primary (a single strand of amino acids), secondary (a folded primary structure), tertiary (multiple folds in the amino acid chain forming a polypeptide) and quaternary (multiple polypeptides folded onto each other). To reach the quaternary structure, many polypeptides must be made. We will talk about examples in a bit.
2. Central dogma is the flow of genetic information from DNA to mRNA to proteins.
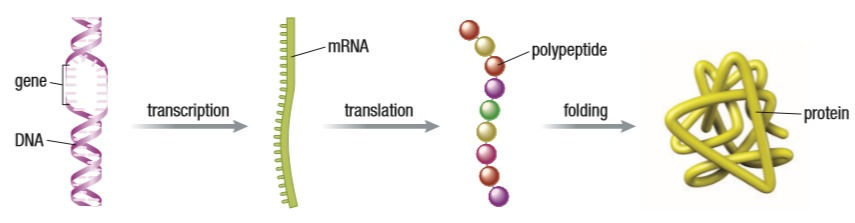
3. Transcription is the process of DNA being read to make mRNA. It’s called transcription because the cell machinery is copying, or rewriting, the same sequence of DNA, in a slightly different way.
4. Translation is the process of mRNA being read to make the required polypeptide. It’s called translation because the cell machinery is expressing the same information in a different language.
5. There are 3 types of RNA:
i) mRNA: messenger RNA that delivers information from the DNA in the nucleus to the ribosomes in the cytoplasm.
ii) tRNA: transfer RNA that delivers the required amino acid to the ribosome, while it is reading the mRNA.
iii) rRNA: ribosomal DNA that binds with proteins to make ribosomes.
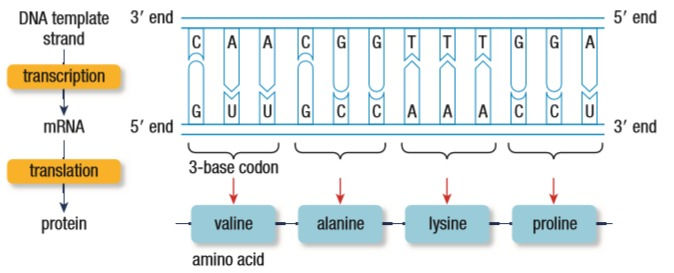
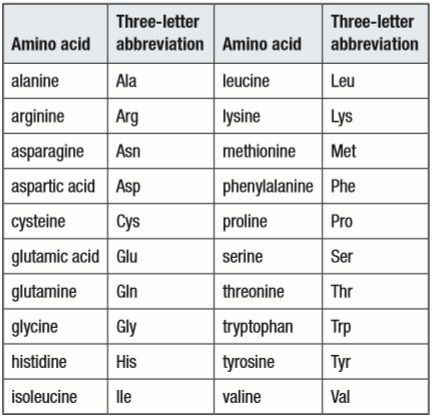
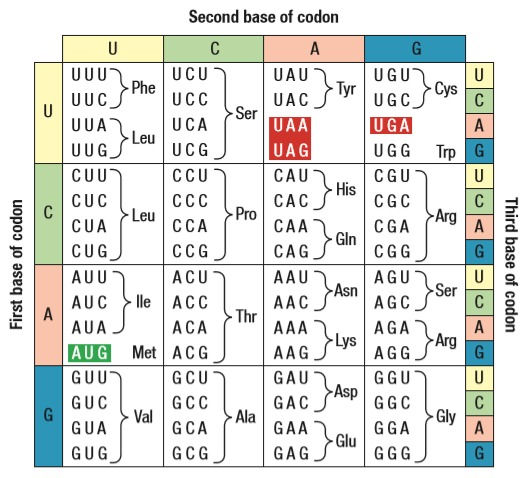
6. RNA, like DNA, has 4 bases. The cell needs 20 amino acids to function. The code for amino acids is 3 letters, or 3 bases, long. With the 4 bases, there are 64 possible combinations of amino acid codes that can be made.
7. DNA bases are Adenine, Thymine, Guanine and Cytosine. The RNA bases are the same with one exception. Uracil takes the place of Thymine. So, when reading the DNA, for every Adenine that needs a complementary Thymine, a Uracil is attached. That was a lot of background information. Now, let’s get to the good stuff.
Transcription is rewriting the DNA code as RNA. mRNA is complementary to the 3’ to 5’ strand of the DNA. This is similar to the DNA replication process from the previous post. There are 3 steps: Initiation, Elongation and Termination.
1. Initiation:
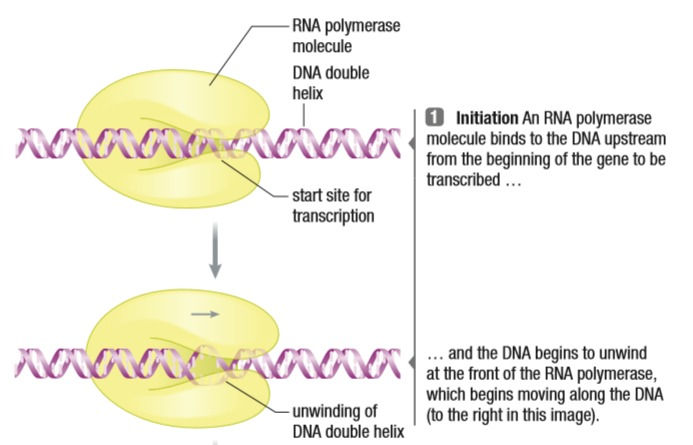
Only one enzyme is needed for this process. Since there is no need for RNA primers, the RNA polymerase gets right to work. A good question to ask is how does the RNA polymerase know where to begin? Specialized sequences of DNA, upstream, or right before, the gene signal the start of the gene. These sequences are called the promoter. The TATA box is a region within the promoter that allows the RNA polymerase to bind to it. It is just a repeating sequence of TATATATA. Thymine and Adenine have only 2 H-bonds, making them easier to break that the 3 H-bonds between Guanine and Cytosine.
Unlike DNA Replication, the strands don’t have to be separated completely. RNA polymerase binds to the site and unwinds the double helix of the DNA, essentially pulling apart the region that needs to be copied. The DNA that has been read leaves through the other side of the polymerase and anneals. *Note; the promoter is not transcribed. It is not found in the final mRNA.*
2. Elongation:
Once the strands are unwound just enough, the mRNA is formed. Just like DNA, mRNA is made in the 5’ to 3’ direction. Only one strand, the 3’ to 5’ strand is read.
*Note: the 5’ to 3’ strand of the DNA that is not read, is called the coding strand. The reason is that since the 5’ to 3’ strand is complementary to the 3’ to 5’ strand and so is the mRNA, the sequence of the coding strand and the mRNA is almost the same (except the mRNA has U instead of T). The 5’ to 3’ strand is not copied because that would give a different sequence than what is needed.*
As the polymerase moves, reading the DNA in the 3’ to 5’ direction, the chain of complementary bases forms until the polymerase hits the end of the gene.
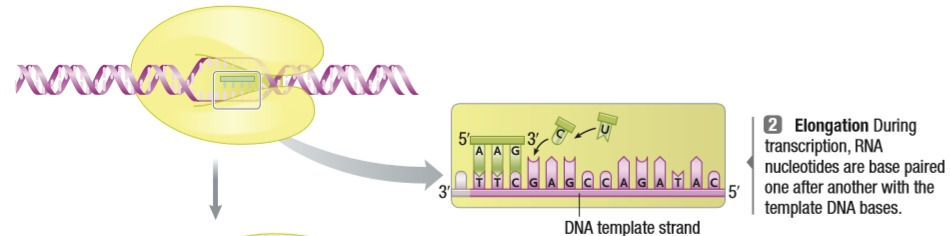
3. Termination:
Like everything else, there is also a sequence of DNA that tells the polymerase when to stop. In eukaryotes, it’s a chain of AAAAAAA that gets translated into UUUUUUUU.
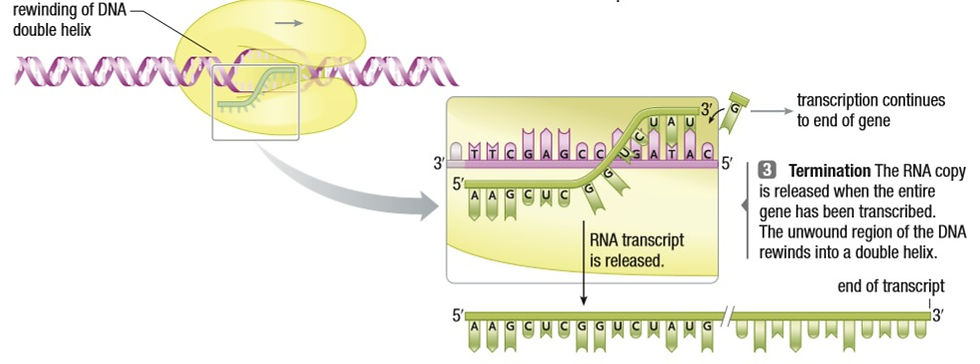
In Prokaryotes, the mRNA made in transcription is final, ready to be used. In Eukaryotes, the mRNA has certain regions that must be removed before it is ready to be read by a ribosome. Other modifications are also made.
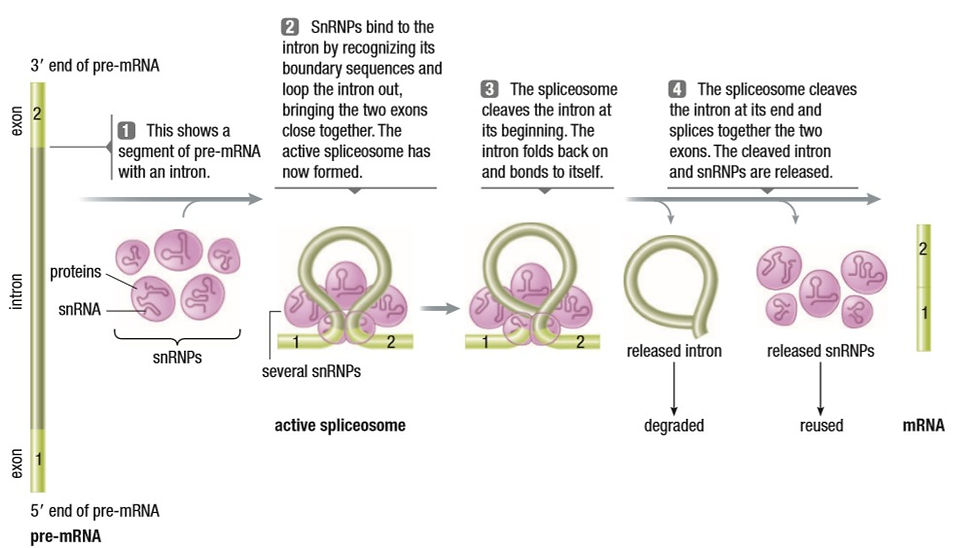
In Eukaryotic genes, there are regions called exons (areas that are executed or expressed) and introns (non-coding areas that must be removed). Splicing occurs with the help of Spliceosomes. They are enzyme-protein complexes formed between the mRNA and small nuclear ribonucleoproteins (snRNPs - pronounced snurps). They cut the introns out and join the exons together. Depending on how they cut the introns and which introns they cut, different strands of mRNA can be formed.
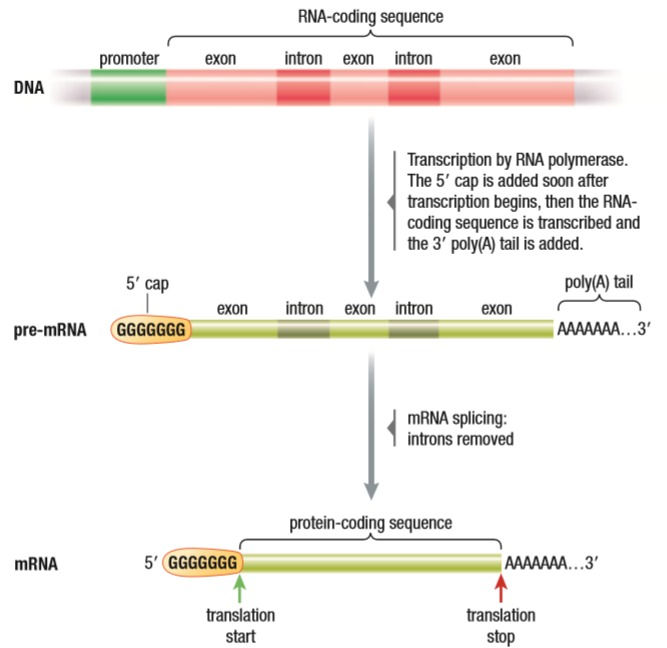
Other modifications done are capping and tailing. 7 Guanines are attached to the start of the mRNA to let the ribosome know where to attach. A chain of 50-250 Adenines is added to the end, called a Poly-A tail; done by the poly-A polymerase. This protects the mRNA from enzymes in the cytoplasm.
DNA and RNA have similarities and differences:

There are some similarities and differences between DNA Replication and Transcription

Translation uses the mRNA to make a polypeptide chain. It is a bit similar to Transcription. Required components are tRNA, ribosomes, mRNA strand and amino acids. This happens in the rough endoplasmic reticulum and the cytoplasm.
There are 3 steps: Initiation, Elongation and Termination.
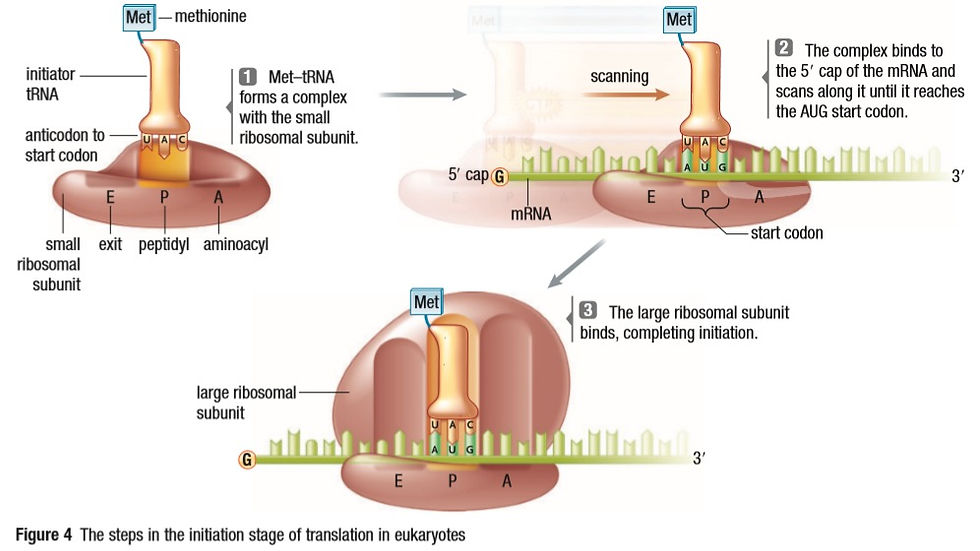
1. Initiation:
The process begins with the ribosomes attaching to the 5’ cap. The mRNA is 5’ to 3’ and that is the direction the ribosomes read it. The ribosome looks for a specific codon, a 3-letter sequence that codes for an amino acid. The first codon is always AUG that codes for Methionine. This sets the reading frame. After the AUG codon, every 3 letters make a codon.
So, for a sequence GGGGGGGUGCAAUGCGAUGUUGA, the ribosome attaches at the 7 Gs and looks for the 1st AUG. CGA will be the next codon, UGU the next and UGA the next. Without this, the reading frame would start at UGC and the whole sequence would be different. The polypeptide chain made will also be different.
Next, we talk about the role of tRNA. tRNA is a short RNA strand that goes from 3’ to 5’. It has an amino acid on the 3’ end and an anticodon that is complementary to the codon it holds an amino acid for. The tRNA that carries Met will have the anticodon UGC, which is complementary to AUG.

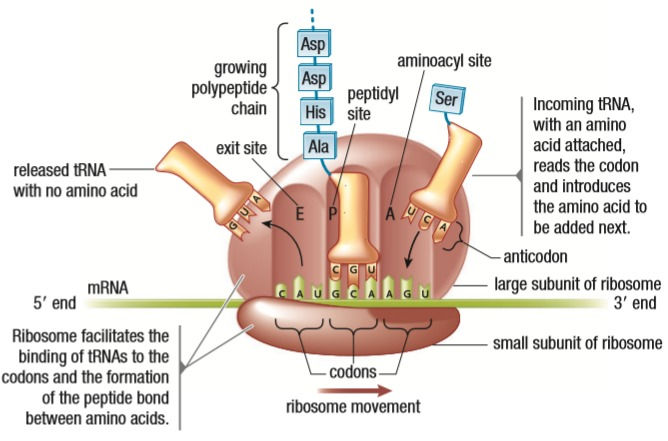
The ribosome has 3 sites: the aminoacyl site (A site) where the tRNA enters, the peptidyl site (P site) where the tRNA carrying the growing polypeptide chain is attached and lastly, the exit site (E site), where the tRNA exits the ribosomal complex.
2. Elongation:
Let’s assume the tRNA with the Met amino acid is already in the P site. The next tRNA comes into the ribosome with the amino acid for the codon being read. With the help of an enzyme, peptidyl transferase, the amino acid from the first tRNA is moved to the second. A peptide bond forms between the two amino acids. The first tRNA leaves the ribosome through the E site and the second tRNA moves to the P site. The process repeats for all the following codons until it is time to stop.
*Note: As we talked about earlier, there are 64 possible codon combinations. So, why are there only 20 amino acids? The transcription process has no proofreading mechanism, no way to check for errors. To compensate for this, there is usually more than one combination of the 3 letters that code for the same amino acid. There are 4 codons that make Proline. The Wobble Hypothesis states that the third base of a codon may differ between two or more codons that code for the same amino acid. So, the third base leaves a little room for error.*
3. Termination:
When the ribosome reaches UAA, UAG, or UGA, no tRNA comes. Instead, a protein comes a binds to the A site, dismantling the whole complex, releasing the complete polypeptide chain and the ribosomal subunits.
The polypeptide is still not ready to be used. It passes through the rest of the organelles in the endomembrane system. It may go to the smooth endoplasmic reticulum to become a protein for lysosomes or it may go to the Golgi complex, where it is modified to be sent to the cell membrane. There, the protein becomes a membrane protein.
A lot of genes are specific to the function of the cell and are dependent on the type of cell. They may be one in some cells and off in others. Housekeeping genes code for proteins needed in all cells, like the ones needed during respiration, metabolism, growth etc. There has to be a function in the cell that allows the genes to be regulated. For the sake of simplicity, we’ll talk about prokaryotic gene control. We’ll focus on 2 examples: Lac operon and trp operon.
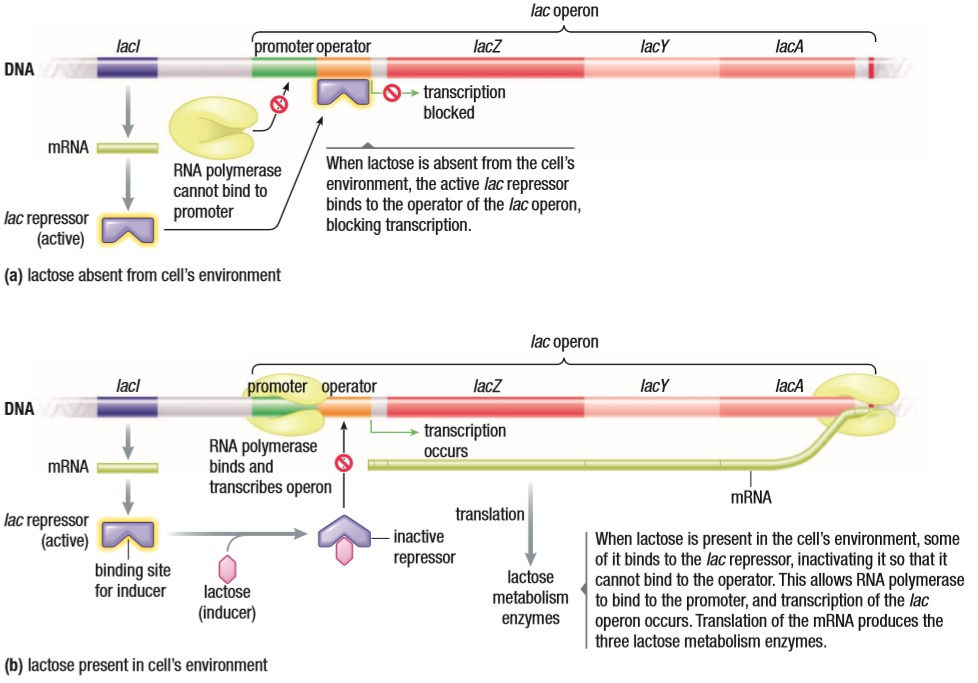
Lac operon is a cluster of 3 genes that code for the proteins that break down lactose. The operon has a promoter, and operator and coding regions. The function of the operator is to control transcription. The amount of lactose in the cell fluctuates and it is a waste of energy to produce proteins that break down lactose when there isn’t any available to be broken down. In such a situation, a repressor comes in handy. Upstream from the lac operon is a gene for the lac repressor. This gene is always expressed. It is always in its active form and when the lactose levels are low in the cell, it binds to the operator. This prevents the RNA polymerase from reading the genes required and no lac proteins are made. When the lactose levels increase, the lactose molecules act as inducers. They bind to the lac repressor and inactivate it. With nothing bound to the operator, the RNA polymerase reads the genes and lac genes are expressed. The lactose is broken down, the levels decrease, and the repressors return to its active form. It binds to the operator and waits for the lactose levels to increase again.
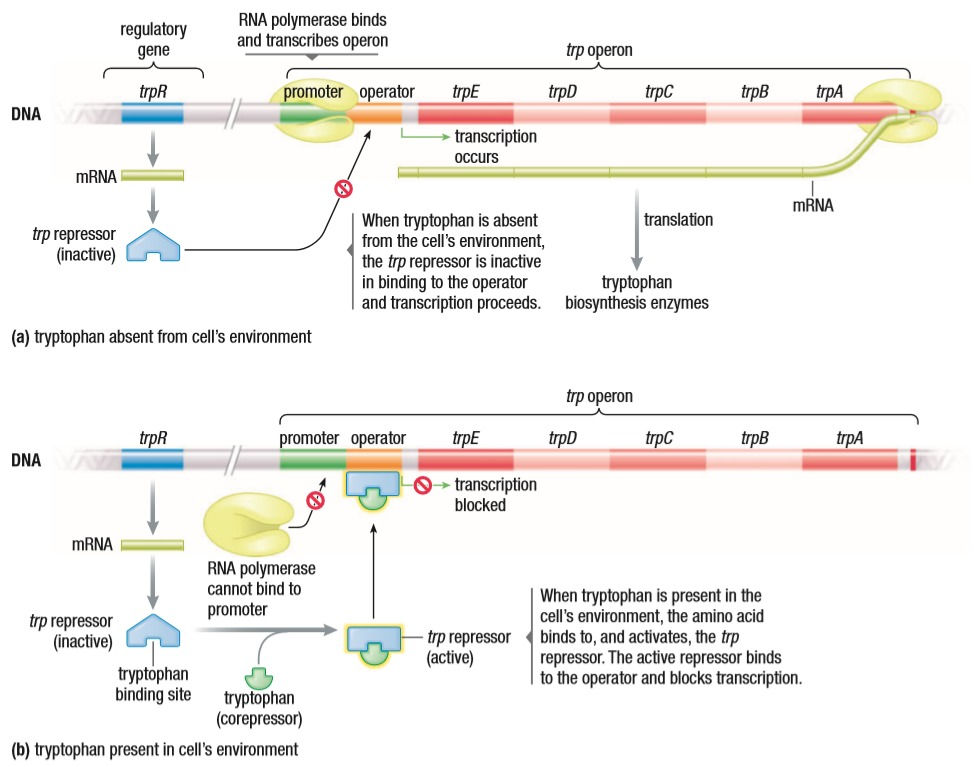
The trp operon has almost the opposite story. Tryptophan is an amino acid required by the cell. Some organisms can get trp from their surroundings and make it in their cells as well. The cell has to know when to make trp and when to stop depending on the availability of trp in its surroundings. A trp repressor is always synthesized. It is always in its inactive form when trp levels are low in the surroundings. This means the RNA polymerase reads the trp genes and trp is made. When the cell’s surroundings have trp that can be absorbed, the trp helps activate the repressors and, together, they repress the gene that codes for trp. Trp acts as a corepressor. This is an example of negative feedback, which is the response an organism has to changes in the environment. The organism then works accordingly to re-establish balance or equilibrium.
Eukaryotic cells have their own gene control mechanisms. Transcriptional gene control regulates which genes are transcribed and at what rate does the transcription occur. Post-transcriptional controls the pre-mRNA becoming mRNA. So, it controls the availability of mRNA molecules to ribosomes. Translational regulate how much and how quickly mRNA will be translated into proteins. Finally, post-translational controls when the characteristics of the proteins; when do they become fully functional, how long are they functional, and when do they degrade.
Cancer cells lack this mechanism. Telomere production is controlled by gene expression and since the lengthening is not controlled in cancer cells, they grow out of control.
Mutations are changes in the DNA sequence due to error in replication, or environmental reasons. Not all mutations are negative. They may have a positive effect, like lactose tolerance. Small-scale mutations are mutations of individual base pairs or of small groups of base pairs. The single base-pair mutations are called point mutations. Some types of point mutations are substitution, where one base is switched for another, insertion or deletion, where a base pair is added or removed, or inversion, where two base pairs switch places.
There are 4 categories of mutations:
1. Missense mutation: when a change of base pair(s) results in a different amino acid being coded. The synthesized protein will have a different sequence and, consequently, a different structure. The protein might become non-functional or may function differently. This could prove to be positive if the effect produced is desirable. Ex: UCC-> UCG
2. Nonsense mutation: when the change results in a premature stop code in the gene. The polypeptide is cut short. It’s called a nonsense mutation because the polypeptide will, likely, not function properly. Ex: UAC->UAG
3. Silent mutation: when the change does not affect how the gene functions. The mutation still codes for the same amino acid as the non-mutated sequence, so the final protein is not affected.
4. Frameshift mutation: when nucleotide(s) is/are inserted into or deleted from a DNA sequence. This causes the reading frame of codons to shift. This causes multiple missense and/or nonsense effects. The frameshift mutation “shifts” the reading frame by one or more steps, and every amino acid coded for after this mutation is affected.
Besides small-scale mutations, there can be large scale mutations. The effect is usually amplified. For the sake of keeping this post from getting too long, I’ll name them, and you can research them if you wish to. There are 5 types: Amplification, Deletion, Translocation, Inversion and Trinucleotide Repeat Expansion.
Some mutations can have negative or even deadly effects. Exposure to potential mutagens have a cumulative effect. Many forms of cancer occur most often during old age due to this, after a lot of mutations have accumulated, affecting the cell’s functions.
Our last topic is viruses. Viruses are non-living because they cannot reproduce without a host cell. They cannot perform DNA replication on their own. A virus is just nucleic acids with a protein coat. The reason behind the existence of so many strains is due to error in replication. Here is a picture of how viruses use host cells to replicate.
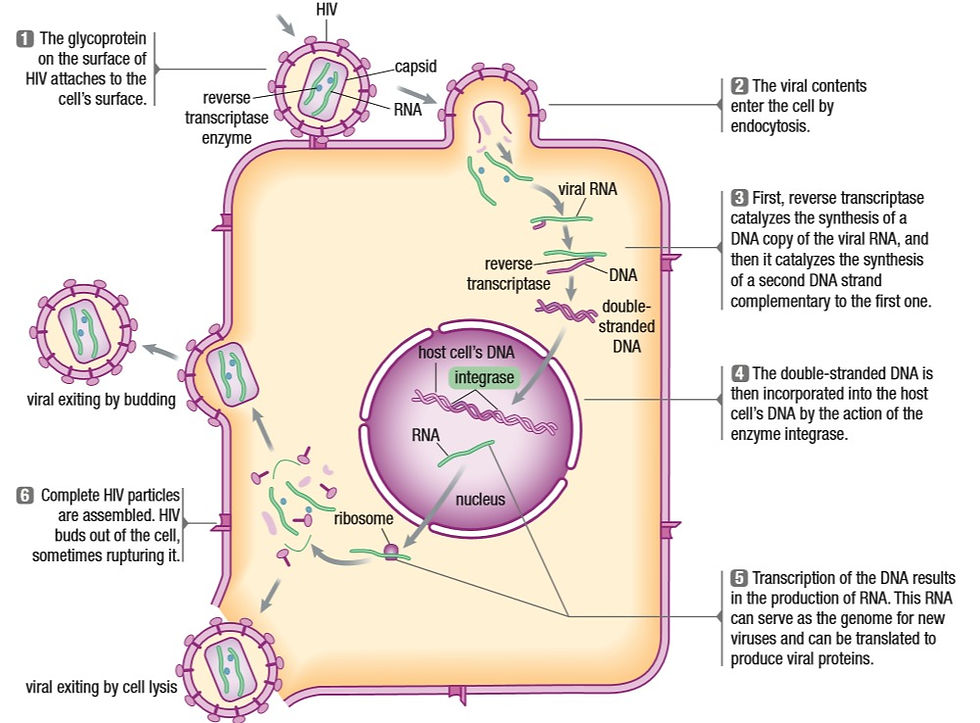
This post is pretty long and there are still things we could have discussed. If you’d like to know more, feel free to let me know and I’ll try to help you. -Aarushi.
APA Citation:
Fraser, D., LeDrew, B., Vavitsas, A., White-McMahon, M. (2012). Biology 12. Toronto: Nelson Education Ltd.



Comments